Case against Manhattan‑scale AI farms and what beats them


The AI future worth building is not Manhattan-sized data-center of GPUs, but shoebox-sized breakthroughs in physics, algorithms, and chips. Human ingenuity, sharpened by constraint, will always outpace concrete and steel.
Backdrop: By know, everyone is aware that Meta has announced Manhattan-sized AI campuses, each drawing up to a gigawatt of power, with projections of 5-gigawatt “titan clusters” in the pipeline. Amazon, Google, and other large corporations are making parallel investments in hyper-scale AI regions, each requiring new substations, gas turbines, and solar fields just to keep the racks alive.
Analysts already warn that U.S. data centers could devour 10–12% of national electricity by 2028 — a staggering diversion of power for a single technology sector.
Even if the world suddenly discovered free, limitless energy, pouring it into AI mega-farms would still be the wrong bet. Energy, abundant or scarce, always carries an opportunity cost: every gigawatt consumed by GPUs is a gigawatt not powering homes, hospitals, transportation, or clean industry.
That’s why the most important benchmark for humanity isn’t the size of a server farm or the number of parameters in a model. It’s tokens (or tasks) per kilowatt-hour — how much useful intelligence we can squeeze from every unit of energy.
Yet the industry is sprinting in the opposite direction.
History, however, tells a different story. Human ingenuity always outpaces brute scale. The supercomputers that once filled rooms are now dwarfed by chips in your pocket. Constraints — whether in energy, silicon, or capital — have always been the crucible for breakthroughs.
The AI race of the future won’t be won by the company with the largest warehouse of GPUs. It will be won by those who deliver the most intelligence per joule, who can bend physics and software to make AI smaller, faster, and vastly more efficient.
1. Scaling Laws Don’t Reward Infinite Growth
Chinchilla scaling laws showed that, for a fixed training budget, smaller models trained longer on more data outperform massive ones trained shallowly. Chinchilla (70B parameters) beat Gopher (280B) while using the same compute — and cut inference cost by being smaller .
More recently, “Inference-Optimal Scaling Laws” (2024) went further: if you account for real-world inference demand, the optimal model is even smaller than Chinchilla predicts .
This means that beyond a certain size, pouring energy into larger clusters is not only wasteful — it’s counterproductive.
2. Small models, big gains: curated data and SLMs (Small-Language Models)
- Phi‑3 (3.8B): Microsoft reports a 3.8B‑parameter model trained on high‑quality/“textbook” data achieving competitive results with far larger LLMs — and running on laptops/phones.
- Media/analyst coverage of Phi‑3 emphasizes the shift to SLMs for most tasks, reserving giant LLMs for rarities.
- TinyStories proves capability emergence below 10M params with carefully designed data — strong evidence that data quality bends the size curve.
Implication: Quality‑per‑Joule is increasingly a data engineering problem, not a size-of-data-center problem.
3. Software that slashes memory traffic (and energy) at inference time
AI’s biggest bottleneck isn’t math — it’s memory movement. New serving techniques reduce IO and thus power draw.
Modern LLM serving is memory/IO‑bound. Techniques that reduce HBM↔SRAM traffic usually save energy and cost:
- FlashAttention: reorganizes attention to cut memory reads/writes, boosting throughput by up to 3× .
- vLLM / PagedAttention: virtualizes KV cache, delivering 2–4× higher throughput with the same hardware .
- Speculative decoding / Medusa: multiple decoding paths in parallel, 2–3× faster generation .
Implication: With smarter kernels and decoding, smaller servers can do what yesterday required a pod.
4. Architectures beyond Transformers: linear‑time and hybrid
Linear-time sequence models like Mamba and RetNet are proving you can cut complexity without losing accuracy. Mamba-2 has shown 5× higher throughput than same-size Transformers, while RetNet combines parallel training with recurrent, low-cost inference.
- Mamba / selective SSMs achieve linear‑time inference and show 5× higher throughput than same‑size Transformers in reported experiments; larger‑scale studies (8B) find Mamba‑2 competitive with Transformers at equal data.
- RetNet provides a retention mechanism with parallel training + low‑cost recurrent inference — designed to cut deployment cost without losing performance.
These architectures are tailor-made for energy-efficient intelligence, not brute-force FLOPs. If the backbone itself scales linearly, you don’t need “Manhattan” to serve long contexts and high QPS.
5. Compression that actually holds up
- SparseGPT prunes LLMs 50–60% in one shot with minimal perplexity hit (loss) — billions of weights can be skipped at inference.
- Quantization: FP8 (standard in NVIDIA Hopper/Blackwell) and BitNet (1.58-bit weights) show near-parity accuracy with orders of magnitude less energy .
Together with quantization (LLM.int8/4‑bit, FP8 training), these methods deliver real energy and memory wins at near‑parity quality.
6. Precision collapse: from FP8 to 1.58‑bit
- FP8 training is now mainstream via NVIDIA Transformer Engine (Hopper/Blackwell), reducing bandwidth and memory pressure during training and inference.
- BitNet b1.58 (ternary weights) matches FP16/BF16 performance with far less compute/memory — and Microsoft ships kernels for CPU inference with 2.4–6.2× speedups.
Implication: If weights/activations drop to ~2 bits without quality loss, “super‑pods” become grossly oversized for many workloads.
7. Edge & mini‑pods: paging, storage, and small accelerators
- Apple's LLM in a Flash: page weights from SSD to DRAM with row/column bundling and windowing, enabling models 2× larger than DRAM to run efficiently on a single box.
- Combine this with SLMs + quantization and consumer‑grade GPUs/NPUs (or tiny racks of them) become viable AI micro‑data-centers for many enterprise apps.
With techniques like this, edge devices and micro-data centers can take over workloads that corporations assume require Manhattan-sized facilities.
8. Hardware horizon: killing the interconnect bottleneck
- Optical I/O chiplets (Ayar Labs TeraPHY) demonstrate <5 pJ/bit at Tbps‑class bandwidth with ns‑scale latency; roadmaps target ~1 pJ/bit. Electrical fabrics struggle to match that energy/bit.
- HBM3E/4 keeps raising bandwidth (>1.2 TB/s per stack), but pin‑limited electrical I/O and memory‑traffic energy remain major constraints — another reason to optimize algorithms first.
- Analog / in‑memory compute is moving from paper to practice for attention and MoE; IBM and others report promising throughput/energy projections as datamovement shrinks.
Even as hardware improves, the biggest lever is less data motion — which favors smaller/sparser models and better kernels over “more racks.”
9. Physics says “you can’t scale watts forever”
Landauer’s limit tells us erasing one bit has a minimum energy cost of:
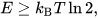
and the only way past it is reversible computation, which is an active research area but far from production. You can’t hand‑wave heat.
Even if Moore’s Law sputters forward, Landauer’s limit reminds us there’s a minimum energy cost to erase a bit. Without breakthroughs in reversible or analog computing, power scaling hits a wall.
Policy reality: The IEA and DOE/NREL document fast growth in data‑center electricity consumption; power availability and cost will ration scale long before “infinite Blackwells” can be delivered.
The U.S. DOE projects data center demand could double in the next five years . Grid bottlenecks, not silicon, may become the limiting factor.
Heat Dissipation Challenges: As power systems increase in scale and complexity, so does the amount of heat they generate. Efficiently dissipating this heat becomes increasingly challenging and can limit the overall efficiency and performance of power generation, transmission, and use, according to the Pacific Northwest National Laboratory. High temperatures can also decrease the efficiency of power generation and transmission, reducing the overall capacity of the grid.
About that “Manhattan‑sized” data center idea
Meta is reportedly exploring 1‑gigawatt‑class AI campuses with 600k+ accelerators and $35–40B annual capex — projects large enough to require dedicated generation (nuclear/renewables). Even boosters admit power is the bottleneck.
Inference‑aware scaling (Sec. 1) and the software/hardware evidence above suggest many enterprises will get better ROI by pushing capability per joule rather than chasing acreage.
A workable metric: tokens (or tasks) per kWh
The lesson across research and physics is clear: AI should be judged not by model size, nor cluster footprint, but by energy productivity.
The field needs to rank models not just by win‑rates but by energy productivity:
- Tokens/sec/Joule at target quality (e.g., MMLU ≥ X).
- Tasks/kWh for your production prompts.
- $ per 1M tokens @ SLA latency (post‑speculative/Medusa).
These are consistent with the Green AI push and the economics embedded in inference‑aware scaling laws.
What to build instead of a mega‑farm?
- SLM‑first stack. Start from Phi‑class SLMs and only escalate to giant LLMs on miss. Use cascades + speculative decoding to keep latency/J down.
- Quantize + prune by default. Deploy 4–8‑bit weights/activations; evaluate BitNet for ternary workloads; add SparseGPT/movement pruning until quality breakpoints.
- Serve with IO‑aware kernels. Standardize on FlashAttention/FlashDecoding++ and vLLM/PagedAttention; measure energy before/after.
- Explore linear‑time backbones. Pilot Mamba‑2/RetNet models on your longest‑context, highest‑QPS services.
- Edge/mini‑pod pilots. Use LLM in a Flash techniques to over‑subscribe DRAM with SSD and deploy small racks at the network edge.
- Co‑design for optics (near‑term) and analog/reversible (long‑term). Track optical I/O chiplets for cluster disaggregation; incubate POCs for analog in‑memory on attention/MoE paths.
- Adopt energy SLAs. Gate launches on tasks/kWh regressions, not just quality deltas.
Bottom line
The evidence says human ingenuity beats acreage. Compute‑optimal training, inference‑aware economics, aggressive compression/quantization, IO‑aware serving, and linear‑time architectures all point to a future where smaller, smarter beats bigger, hungrier. The “machine‑gun in a monkey’s hand” isn’t just wasteful, it's dangerous — it’s soon to be non‑competitive on the unit economics that matter.
Meta, and others may gamble on gigawatt campuses, but history will likely render them as the last of the brute-force monuments — monuments to an era before we learned to do more with less.
The true winners will be those who:
- Train smaller models longer (Chinchilla).
- Invest in data quality, not just parameter count (Phi, TinyStories).
- Exploit software efficiency (FlashAttention, vLLM, speculative decoding).
- Embrace new architectures (Mamba, RetNet).
- And measure success in tokens per kWh, not megawatts per campus.


